Psychology 240 Lectures
Chapter 7
Statistics 1
Illinois State University
J. Cooper Cutting
Fall 1998, Section 04
Your textbook:
- Gravetter, F. J., Wallnau, L. B. (1996). Statistics for the Behavioral Sciences:
A First Course for Students of Psychology and Education, 4th Edition. New York: West Publishing.
Chapter 7: Probability and samples: The distribution of sample means
Last chapter we talked about the probability of finding a particular score, or set of
scores in the population.
Now, we will instead talk about the probability of finding particular samples in the
population.
This is getting closer to inferential statistics. Recall that the goal of inferential
statistics is to make claims about population parameters based on sample
statistics.
So the logic will be something like this. We can't measure the
whole population, so we take a sample. Our best estimate
for the mean of the population will be the mean of our
sample. (remember that it is only an estimate because we
have sampling error before - the difference between a
sample statistic and the corresponding population parameter)
It sounds simple and straight forward, but consider the following:

Suppose that you take 3 different samples from the same population. They are
going to be different from one another. They will have different shapes,
different means, and different variability. So how do you figure out what
the best estimate of the population mean is?
How many possible samples can we take? Infinite (remember that we are sampling
with replacement)
Luckily for us, the huge set of possible samples forms a simple, orderly, and
predictable pattern (a sampling distribution). Because of this, we are able to
base our predictions about sample characteristics on the distribution of
sample means.
The distribution of sample means is the collection of sample means
for all the possible random samples of a particular size (n) that can be
obtained from a population.
A sampling distribution is a distribution of statistics obtained by
selecting all the possible samples of a specific size from a population.
In other words, what we want to do is look at all of the possible samples (of a
particular size, this part is important) and make predictions based on the
properties of all of them.
How do we do this?
The same kind of thing that we've done in the past, we
essentially find the average those properties.
Let's look at a more concrete example (the book's example):
Consider the following population of scores: 2, 4, 6, 8
because this population is so small we actually can know the mean (and variability): m = 5,
but suppose that we didn't, and wanted to be able to make an estimate based on sampling
step 1: pick a sample size: for this example we'll pick samples of n = 2
- we'll talk more about sample size a little later, but typically the bigger your sample
size, the more likely that your samples will be similar to one another (and to
the population as a whole)
step 2: now consider all of the possible samples that you could get, and look at their
distribution
____________________________________
scores sample mean
sample first second (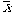 )
1 2 2 2
2 2 4 3
3 2 6 4
4 2 8 5
5 4 2 3
6 4 4 4
7 4 6 5
8 4 8 6
9 6 2 4
10 6 4 5
11 6 6 6
12 6 8 7
13 8 2 5
14 8 4 6
15 8 6 7
16 8 8 8
)
1 2 2 2
2 2 4 3
3 2 6 4
4 2 8 5
5 4 2 3
6 4 4 4
7 4 6 5
8 4 8 6
9 6 2 4
10 6 4 5
11 6 6 6
12 6 8 7
13 8 2 5
14 8 4 6
15 8 6 7
16 8 8 8
Distribution of the sample means
 |
f
2 1
3 2
4 3
5 4
6 3
7 2
8 1
|
step 3: Now you're ready to answer questions like: What is the probability of getting a
sample with a mean greater than 7? p( > 7) = ?
look at our distribution of sample means, we find that 1 out of 16 have a
mean greater than 7. So that's our answer
In our example we've simplified things greatly. We have a really small population, and we took a pretty small sample. Most situations, however, will be much more complex. Lucky for us there are some properties of means of samples that will help us out.
shape: the shape of the distribution of sample means tends to be a normal
distribution. In fact, when n is large (around 30 or more), the distribution
of sample means is almost perfectly normal. You guessed it, this means
that we'll be seeing the unit normal table again in the near future.
does this make sense? It should. If you select a bunch of samples
from the same population, the most of the means should "pile up"
near the population mean m (if they don't then you must have some
kind of bias in your sample)
mean:
the average of all of the sample means will equal the mean of the
population. The average of all of the sample means is called the expected
value of . It is "expected" because it should be a value near the
population mean m . (note: often symbolized as: m , but your book will
usually just use m )
Look at our example, the expected value of (the mean of the sample means) is:
2 + 3 + 4 + 5 + 3 + 4 + 5 + 6 + 4 + 5 + 6 + 7 + 5 + 6 + 7 + 8 = 80 = 5.0
16 16
note: if n is large enough, then the distribution is normal, which also
means that it is unimodal and symmetrical, which means that the
mean = median = mode
variability: the standard deviation of the distribution of sample means is called
the standard error of
standard error of =
 = standard distance between and m .
= standard distance between and m .
in other words, this statistic describes the standard (typical/average)
distance from the mean. In this case it is the distance between the
sample mean and the population mean m .
the major purpose/use of the standard error of is that it tells us how well
the sample mean estimates the population mean. In other words,
how big is the sample error.
the numerical value of the standard error is determined by two characteristics: the
variability of the population & the size of the sample
1) the variability of the population - the bigger the variability
of the population, the more variability you'll have in the
sample means.

large s
big differences from the pop mean |

small s
small differerences from the pop mean |
2) the size of the sample - the larger your sample size (n), the
more accurately the sample represents the population. This
is known as the law of large numbers .
think of it this way:
suppose that you have a population of 1,000
students. You want to know the average SAT score
of the entire population.
 |
- If I randomly selected 1 student, how
accurately will that student's score
predict the population's score? |
 |
- Suppose that I take 5 students. Are things
more accurate?
|
 |
- what about 100 students? |
these two characteristics are combined in the formula for standard error.
standard error of = = 
All of these properties (shape, mean, variability) are covered in the Central Limit Theorem
Central Limit Theorem: For any population with mean m and standard
deviation s, the distribution of sample means for sample size n will
approach a normal distriution with a mean of m and a standard deviation
of as n approaches infinity.
So, when n is large (at or above 30): ~ N (m , )
(reminder: n = the number of scores in the sample)
Now let's bring probability back into the picture.
Example:
Consider the following situation. An instructor is interested in the IQ of her
students. She has 9 students in her class and thinks that they are, on the average,
really smart. What is the probability that the group of students has a mean greater
than or equal to 112?
recall for standardized IQ test: m = 100, s = 15
First we need to get the distribution of the samples (note: we'll assume a normal
distribution even though n is less than 30.)
~ N (m, ) = N(100, 5)
Now we need to figure out the z-score that corresponds to this sample mean:
the z-score pretty much looks like what we've used before: Z = 
Does this answer make sense?
 |
- at first it looks wrong
- it seems like 112 should be less than a z = 1, because 115 is where z should equal 1 |
 |
- however, we must remember that this isn't the correct distribution to be looking at, we need to look at the distribution of sample means.
-we know that the distribution of sample means has a standard error = 5 and a mean = 100.
- So 112 should have a z >2 |
Example:
How high a mean would a group of 25 have to have on IQ to be in the top
10% of the IQ distribution for groups of this size?
so for our example:
step 1: look at unit normal table for 90%
step 2: = 1.28 * + 100 = (1.28)(3) + 100 = 103.84
so, for a group of 25 people, they'd have to have a mean of just under 104 to be in
the top 10%
Suppose that we asked the same question for a smaller sample, n = 16? How does the answer change?
step 1: look at unit normal table for 90%
step 2: = 1.28 * + 100 = (1.28)(3.75) + 100 = 104.80
so, for a group of 16 people, they'd have to have a mean of over 104 to be in
the top 10%
What about other sample sizes?
n = 9
= 1.28 * + 100 = (1.28)(5) + 100 = 106.40
n = 4
= 1.28 * + 100 = (1.28)(7.5) + 100 = 109.60
n = 1
= 1.28 * + 100 = (1.28)(15) + 100 = 119.20
Note: the if n = 1, the standard error equals the population standard deviation
So the take home message is: the smaller your sample size, the larger your sampling error (standard error, ).
Interpreting sampling variance:
We've already talked about the first two:
A) Sampling Error: any one sample may over or under estimate (with about half
of each).
B) Standard Error: most of the means will be close to m , but some are further
away. The variability of these sample means represents the standard
distance between m and, or the "standard" error distance. It defines the
relationship between sample size and the accuracy with which represents
m .
We've sort of talked about these two, but not by name:
C) Reliability: As the standard error gets smaller, then our confidence in as
an estimate of m increases.
- Reliability roughly refers to how similar different samples (of the
same size) from the same population are to one another. If
most of the samples have similar statistics (e.g., means, and
stdev) then reliability is high. If most of the samples have
different statistics, then reliability is low.
- We've seen this in our examples. As n gets larger, the sample
statistics become better estimates of the population
parameters. So, repeated samples of a large n, will usually
have similar statistics (all near the population parameters).
D) Stability: The smaller the standard error is, the less likely adding or deleting
or changing a single score would chage the estimate of m .
- We've discussed what happens to population means and standard
deviations when you change scores in the distribution (e.g.
add a score, change a score, etc.). What happens to the
standard error if we make changes?
consider the population X ~ N(50, 10) [m = 50; [s = 10]
suppose that we take two samples:
Now suppose that we add a new score of 20 to each sample.
sample 1: 50 * 4 = 200 --> (200 + 20)/5 = 44 is new mean
sample 2: 50 * 100 = 5000 --> 5020/101 = 49.7 is new mean
So sample 2 is morestable to change than sample 1. More generally, the smaller the standard error, the more stable the sample.
Go Chapter 6: Probability
Go to Chapter 8: Introduction to hypothesis testing
Return to Psych 240 syllabus page
Return to Psych 345 syllabus page
Return to Statistics Lectures page
Return to Illinois State University Home Page
Return to Illinois State University Psychology Home Page
If you have any questions, please feel free to contact me at
cutting@main.psy.ilstu.edu.